제품가격 예측모델 코드 실습.
price 를 예측하는 회귀문제이지만, 비정형의 텍스트 형태 피쳐가 포함된 데이터셋이다.
데이터의 전처리부터, 예측모델 학습, 평가까지 전반적인 프로세스 흐름을 만들어본다.
(출처 - 파이썬 머신러닝 완벽가이드)
1. 데이터 탐색(EDA) & 전처리 데이터 불러오기. price 가 타겟이고, 나머지 7개 피처중에 4개정도가 비정형의 텍스트형 피쳐다.
from sklearn . linear_model import Ridge , LogisticRegression
from sklearn . model_selection import train_test_split , cross_val_score
from sklearn . feature_extraction . text import CountVectorizer , TfidfVectorizer
import pandas as pd
mercari_df = pd . read_csv ( 'mercari_train.tsv' , sep = ' \t ' )
print ( mercari_df . shape )
mercari_df . head ( 3 ) #백오십만개 가량의 레코드, 7개피처 1개 타겟
NULL 값을 가지고 있는 컬럼들에서는 NULL 값 특정값으로 변환
print ( mercari_df . info ())
mercari_df [ 'brand_name' ] = mercari_df [ 'brand_name' ]. fillna ( value = 'Other_Null' )
mercari_df [ 'category_name' ] = mercari_df [ 'category_name' ]. fillna ( value = 'Other_Null' )
mercari_df [ 'item_description' ] = mercari_df [ 'item_description' ]. fillna ( value = 'Other_Null' )
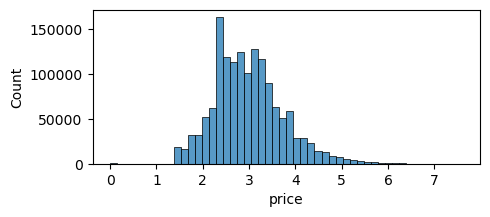
회귀문제의 target값은 예측성능을 위해 어느정도 정규분포 모양을 띄는것이 매우 중요하다.
히스토그램을 통해 본 price 의 분포는 심하게 right skewed 되어있음 → log1p 를 이용해 로그변환하여 정규화 시켜줌
log1p로 정규화한 데이터는 expm1 으로 간단하게 원복할 수 있는 장점을 갖는다.
import matplotlib . pyplot as plt import seaborn as sns
y_train_df = mercari_df [ 'price' ]
plt . figure ( figsize = ( 5 , 2 ))
sns . histplot ( y_train_df , bins = 100 )
plt . show ()
import numpy as np
y_train_df = np . log1p ( y_train_df )
plt . figure ( figsize = ( 5 , 2 ))
sns . histplot ( y_train_df , bins = 50 )
plt . show ()
mercari_df [ 'price' ] = np . log1p ( mercari_df [ 'price' ])
Categorical 한 피쳐인 shipping 과 item_condition_id를 봤을때, shipping은 0,1 binary class 로 고르게 분포되있지만, item_condition의 경우 1,2,3 에 대부분 데이터 몰려있음 (4,5는 극히일부)
mercari_df [ 'shipping' ]. value_counts ()
mercari_df [ 'item_condition_id' ]. value_counts ()
category_name 컬럼은 '/' 두개로 분리된 형식의 텍스트. 따라서 / 를 기준으로 대,중,소 카테고리로 나눠주는 함수 생성
# apply lambda에서 호출되는 대,중,소 분할 함수 생성, 대,중,소 값을 리스트 반환
def split_cat ( category_name ):
try :
return category_name .split( '/' )
except :
return [ 'Other_Null' , 'Other_Null' , 'Other_Null' ]
# 위의 split_cat( )을 apply lambda에서 호출하여 대,중,소 컬럼을 mercari_df에 생성.
mercari_df [ 'cat_dae' ], mercari_df [ 'cat_jung' ], mercari_df [ 'cat_so' ] = \
zip ( * mercari_df [ 'category_name' ]. apply ( lambda x : split_cat ( x )))
# 대분류만 값의 유형과 건수를 살펴보고, 중분류, 소분류는 값의 유형이 많으므로 분류 갯수만 추출
print ( '대분류 유형 : \n ' , mercari_df [ 'cat_dae' ]. value_counts ())
print ( '중분류 갯수 :' , mercari_df [ 'cat_jung' ]. nunique ())
print ( '소분류 갯수 :' , mercari_df [ 'cat_so' ]. nunique ())
2. 피처 인코딩 & 피처 벡터화
텍스트 형식의 피쳐들은 인코딩(원-핫) 혹은 피쳐 벡터화 할것으로 구분한 뒤 피쳐에 맞게 처리한다. 일반적으로 데이터의 종류가 너무 많으면 피쳐 벡터화를, 허용가능한 수준이면 원핫 인코딩을 한다. (특히 선형 회귀의 경우 원-핫 인코딩이 선호된다) 피쳐 벡터화의 경우 짧은 텍스트는 Count기반, 긴 텍스트는 TF-IDF 기반으로 벡터화한다.
- 피쳐별 변환계획 수립 ① 우선 brand_name 피쳐는, 종류가 많긴 하지만 대부분 명료한 문자열로 되어있기에 인코딩 대상 피쳐로 고려한다.
print ( 'brand name 의 유형 건수 :' , mercari_df [ 'brand_name' ]. nunique ()) print ( 'brand name sample 5건 : \n ' , mercari_df [ 'brand_name' ]. value_counts ()[: 5 ])
② name 컬럼은 종류가 너무 많다. (데이터 레코드 대비, 종류의 개수가 80%
수준으로 거의 고유값으로 볼 수 있다) 따라서 인코딩보다는 피처 벡터화가 적합하며, 텍스트가 다소 적은 단어뭉치로 되어있기 때문에 Count기반 피쳐 벡터
화를 진행한다.
print ( 'name 의 종류 갯수 :' , mercari_df [ 'name' ]. nunique ())
print ( 'name sample 7건 : \n ' , mercari_df [ 'name' ][: 5 ])
③ 앞서 대/중/소 3개의 피쳐로 분류했던 category_name 피처는 각각 종류가 많지 않기 때문에 (1000개 미만) 원핫코딩을 적용한다.
for i in [ 'cat_dae' , 'cat_jung' , 'cat_so' ]:
print ( i , mercari_df [ i ]. nunique (), '---' , sep = ' \n ' ) # 결과값: cat_dae 11 , cat_jung 114, cat_so 871
④ shipping, item_condition_id 2개 피쳐는 숫자의 의미를 갖지 않는 categorical 데이터이기 때문에, 원-핫 인코딩 진행
⑤ item_description 피쳐의 경우, 인코딩을 하기에 종류가 너무 많고, 텍스트의 길이 또한 길기 때문에 TF-IDF 기반의 피쳐벡터화를 진행한다.
pd . set_option ( 'max_colwidth' , 200 ) #DataFrame 열 최대 넓이 직정
print ( 'descript의 종류 갯수 :' , mercari_df [ 'item_description' ]. nunique ())
# item_description의 평균 문자열 개수
print ( 'item_description 평균 문자열 개수:' , mercari_df [ 'item_description' ]. str . len (). mean ())
mercari_df [ 'item_description' ][: 2 ]
①~⑤ 과정으로 categorical 혹은 text 기반 피쳐들의 모습에 대해 살펴보고, 피쳐 변환 계획을 세웠으니 아래와 같이 실제 인코딩 및 피쳐 벡터화를 실행한다.
- 피쳐 인코딩 및 벡터화 실행 먼저 name, item_description 두가지 피쳐는 각각 Count, TF-IDF 기반의 피쳐 벡터화를 진행한다.
# name 속성에 대한 feature vectorization 변환
cnt_vec = CountVectorizer ()
X_name = cnt_vec . fit_transform ( mercari_df .name)
# item_description 에 대한 feature vectorization 변환
tfidf_descp = TfidfVectorizer ( max_features = 50000 , ngram_range = ( 1 , 3 ) , stop_words = 'english' )
X_descp = tfidf_descp . fit_transform ( mercari_df [ 'item_description' ])
print ( 'name vectorization shape:' , X_name . shape )
print ( 'item_description vectorization shape:' , X_descp .shape)
Vectorizer로 반환된 X_name, X_descp은 CSR 형식의 희소행렬이다. 벡터화된 피쳐의 개수가 10만개 이상의 희소행렬 형태이기 때문에 X_name, X_descp은 앞으로 인코딩할 cateogry, brand_name, shipping, item_condition_id 피쳐들과 같이 결합하여 데이터셋으로 재구성해야한다.
그러려면 인코딩 대상 컬럼도 희소행렬 형식으로 인코딩 해야한다.
사이킷런의 원-핫 인코딩 클래스 종류는 OneHotEncoder / LabelBinarizer 두개이고, 각각 반환값이 밀집/희소행렬로 다름
from sklearn . preprocessing import LabelBinarizer
# brand_name, item_condition_id, shipping 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb = LabelBinarizer ( sparse_output = True )
X_brand = lb_brand_name.fit_transform( mercari_df [ 'brand_name' ])
lb_item_cond_id = LabelBinarizer ( sparse_output = True )
X_item_cond_id = lb_item_cond_id . fit_transform ( mercari_df [ 'item_condition_id' ])
lb_shipping = LabelBinarizer ( sparse_output = True )
X_shipping = lb_shipping . fit_transform ( mercari_df [ 'shipping' ])
# cat_dae, cat_jung, cat_so 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb_cat_dae = LabelBinarizer ( sparse_output = True )
X_cat_dae = lb_cat_dae . fit_transform ( mercari_df [ 'cat_dae' ])
lb_cat_jung = LabelBinarizer ( sparse_output = True )
X_cat_jung = lb_cat_jung . fit_transform ( mercari_df [ 'cat_jung' ])
lb_cat_so = LabelBinarizer ( sparse_output = True )
X_cat_so = lb_cat_so . fit_transform ( mercari_df [ 'cat_so' ])
- 피쳐 벡터화&인코딩 변환한 피쳐(희소행렬) 결합 결합된 데이터는 타입,크기만 확인하고 메모리에서 삭제한다. 메모리의 양이 커서 PC에서 메모리 오류 발생가능하다.
(예측모델 사용시에만 다시 결합해서 이용한다) 결합된 데이터는 인코딩,벡터화한 8개 피쳐의 반환된 희소행렬을 밀집행렬로 변환했을 때 컬럼수 합과 같다.
from scipy.sparse import hstack
import gc
sparse_matrix_list = ( X_name , X_descp , X_brand , X_item_cond_id ,
X_shipping , X_cat_dae , X_cat_jung , X_cat_so )
# 사이파이 sparse 모듈의 hstack 함수를 이용하여 앞에서 인코딩과 Vectorization을 수행한 데이터 셋을 모두 결합.
X_features_sparse = hstack( sparse_matrix_list ).tocsr()
# hstack(행렬 리스트).tocsr() 의 역할은 희소행렬 리스트들을 가로로 쌓은 희소행렬로 만든 뒤 CSR 형식으로 저장한다는 의미
print ( type ( X_features_sparse ), X_features_sparse .shape)
# 데이터 셋이 메모리를 많이 차지하므로 사용 용도가 끝났으면 바로 메모리에서 삭제.
del X_features_sparse
gc . collect () # del 변수를 해도 실제 메모리 상에 삭제가 안되기 때문에 gc(garbage collection)을 통해 메모리에서 삭제
3. 회귀 모델 구축/학습/예측/평가 평가함수와 학습함수를 사용자함수로 따로 만들어 놓고, 여러가지 모델로 학습/예측/평가 비교해본다.
- 평가함수 만들기 평가지표는 RMSLE (낮은 가격보다 높은가격에서 상대적으로 더 오류가 커지는 것 방지)
타겟값인 price를 이미 log변환해뒀기 때문에 RMSLE 적용전에 expm1로 데이터 원복후 적용해야함
def rmsle ( y , y_pred ):
# underflow, overflow를 막기 위해 log가 아닌 log1p로 rmsle 계산
return np . sqrt ( np . mean ( np . power ( np . log1p ( y ) - np . log1p ( y_pred ), 2 )))
def evaluate_org_price ( y_test , preds ):
# 원본 데이터는 log1p로 변환되었으므로 exmpm1으로 원복 필요.
preds_exmpm = np . expm1 ( preds )
y_test_exmpm = np . expm1 ( y_test )
# rmsle로 RMSLE 값 추출
rmsle_result = rmsle ( y_test_exmpm , preds_exmpm )
return rmsle_result
- 학습/예측 함수 만들기 model 에는 estimator를, matrix_list 에는 결합해야하는 희소행렬리스트를 입력한다.
결합된 희소행렬 피쳐데이터와, 기존 라벨을 이용해 입력된 회귀모델로 예측된 값과 테스트 라벨을 반환한다.
def model_train_predict ( model , matrix_list ):
# scipy.sparse 모듈의 hstack 을 이용하여 sparse matrix 결합
X = hstack( matrix_list ).tocsr()
X_train , X_test , y_train , y_test = train_test_split ( X , mercari_df [ 'price' ],
test_size = 0.2 , random_state = 156 )
# 모델 학습 및 예측
model .fit( X_train , y_train )
preds = model .predict( X_test )
# 메모리를 위해 다 쓴 원본데이터는 삭제해줌
del X , X_train , X_test , y_train
gc . collect ()
return preds , y_test
Ridge regression 모델을 통한 학습/예측/평가 진행. Item_Description 을 빼고도 평가했을 때 필요한 피쳐임을 알 수 있음
linear_model = Ridge ( solver = "lsqr" , fit_intercept = False )
sparse_matrix_list = ( X_name , X_brand , X_item_cond_id ,
X_shipping , X_cat_dae , X_cat_jung , X_cat_so )
linear_preds , y_test = model_train_predict ( model = linear_model , matrix_list = sparse_matrix_list )
print ( 'Item Description을 제외했을 때 rmsle 값:' , evaluate_org_price ( y_test , linear_preds ))
sparse_matrix_list = ( X_descp , X_name , X_brand , X_item_cond_id ,
X_shipping , X_cat_dae , X_cat_jung , X_cat_so )
linear_preds , y_test = model_train_predict ( model = linear_model , matrix_list = sparse_matrix_list )
print ( 'Item Description을 포함한 rmsle 값:' , evaluate_org_price ( y_test , linear_preds ))
LightGBM 회귀모델 진행결과, Ridge 선형회귀 대비 성능 우수함
from lightgbm import LGBMRegressor
sparse_matrix_list = ( X_descp , X_name , X_brand , X_item_cond_id ,
X_shipping , X_cat_dae , X_cat_jung , X_cat_so )
lgbm_model = LGBMRegressor ( n_estimators = 200 , learning_rate = 0.5 , num_leaves = 125 , random_state = 156 )
lgbm_preds , y_test = model_train_predict ( model = lgbm_model , matrix_list = sparse_matrix_list )
print ( 'LightGBM rmsle 값:' , evaluate_org_price ( y_test , lgbm_preds ))
서로다른 두개의 회귀모델을 가중평균하는 간단한 앙상블로 성늘 향상 만듬 (회귀에서는 이렇게 가중평균으로도 간단한 앙상블을 수행하기도 하는데, 가중 비율에 대한 명확한 가이드는 없고 주로 성능높은 모델의 가중을 높임)
preds = lgbm_preds * 0.45 + linear_preds * 0.55
print ( 'LightGBM과 Ridge를 ensemble한 최종 rmsle 값:' , evaluate_org_price ( y_test , preds ))















댓글