반응형
Index
● Logistic Regression (로지스틱 회귀)
- 모델의 모형은 선형회귀와 비슷하지만 (입력변수가 Continous 하고, 회귀계수가 선형) 예측하고자 하는 종속변수가 {0,1} 의 Binary 한 값이기 때문에 Binary Classification, 분류모델에 해당한다.
- 하지만 결국 continuous한 P(Y=1 | X) 조건부 확률에 대한 분포를 예측하는 것이기 때문에 Regression이기도 하다.
- LR의 회귀식은 X 의 선형결합식에 Sigmoid 를 씌워 (0,1) 사이의 값으로 만든다. (Logistic function 이라고도 부름)

- Cost function : 일반 회귀에서는 MSE를 활용했다면, 로지스틱회귀는 분류 문제이기 때문에 Cross-Entropy 활용한다.

- 목적함수에 Sigmoid가 들어가면서 비선형함수이기 때문에 최적화를 위해 gradient 계열의 solver인 lbfgs가 주로 쓰임
lr_clf = LogisticRegression(solver=lbfgs, max_iter=600)
● Regression Tree (회귀트리) - CART
- 일반적인 회귀모델은 최적의 회귀계수/회귀함수를 찾는것을 목적으로 학습했다. 반면, 회귀트리는 회귀함수를 기반으로 하지 않고, 결정트리와 같은 트리를 기반으로 한다.
- 분류트리와의 차이점 ① leaf node 의 값이, 분류에서는 레이블의 특정 클래스값인데, 회귀에서는 해당 리프에 속한 데이터의 평균값이다. ② 규칙노드의 분류 기준이, 분류에서는 데이터의 균일도였다면, 회귀에서는 분산의 최소화이다.
- 일반적인 회귀에서는 최적화된 회귀함수의 회귀계수를 반환했다면, 회귀트리에서는 피쳐별 중요도를 feature_importances_ 로 반환한다.

from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
dt_reg = DecisionTreeRegressor(random_state=0, max_depth=4)
rf_reg = RandomForestRegressor(random_state=0, n_estimators=1000)
gb_reg = GradientBoostingRegressor(random_state=0, n_estimators=1000)
xgb_reg = XGBRegressor(n_estimators=1000)
lgb_reg = LGBMRegressor(n_estimators=1000)
def get_model_cv_prediction(model, X_data, y_target):
neg_mse_scores = cross_val_score(model, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)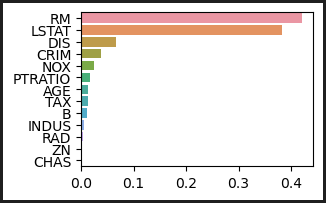
avg_rmse = np.mean(rmse_scores)
print('##### ',model.__class__.__name__ , ' #####')
print(' 5 교차 검증의 평균 RMSE : {0:.3f} '.format(avg_rmse))
# 트리 기반의 회귀 모델을 반복하면서 평가 수행
models = [dt_reg, rf_reg, gb_reg, xgb_reg, lgb_reg]
for model in models:
get_model_cv_prediction(model, X_data, y_target)
# 트리 기반 모델의 feature importance 시각화
feature_series = pd.Series(data=rf_reg.feature_importances_, index=X_data.columns )
feature_series = feature_series.sort_values(ascending=False)
sns.barplot(x= feature_series, y=feature_series.index)
반응형
'Study > ML' 카테고리의 다른 글
| 12. 군집화(Clustering) (0) | 2023.06.05 |
|---|---|
| 11. 차원축소(PCA,LDA,SVD) (0) | 2023.06.01 |
| 9. 회귀(Regression) - 선형회귀 (0) | 2023.05.31 |
| 8. 베이지안 최적화(Bayesian Optimization) (0) | 2023.05.30 |
| 지니계수 (0) | 2023.05.28 |




댓글