반응형
Index
CNN 개요
- CNN은 이미지, 영상 데이터와 같이 huge dimension 이며, 객체의 위치가 바뀌더라도 인식할 수 있는 문제를 해결하기 위해 등장한 모델이다.
- CNN의 가장 큰 두 특징은 ① Weight sharing ② Translation invariance 이다.
- Weight sharing : 아래 비교 그림과 같이 일반적인 FC 구조의 DNN은 항상 입력값으로 이전layer의 모든 노드를 사용하며 입력노드×출력노드 개수 만큼의 weight 파라미터가 필요한 반면, CNN에서는 입력값으로 이전노드의 정해진 사이즈만큼의 노드만 사용하고 weight도 그 사이즈에 맞춘 커널 형식으로 sharing 하게 된다.
- Translation invariance: 객체의 위치가 바뀌거나 조금의 변동이 생기더라도 그 객체를 변함없이 인식할수 있어야 하는데, 이를위해 Max-pooling이라는 방법을 사용하여 특정size 이내 공간의 최대/평균 등 대표값을 사용한다.
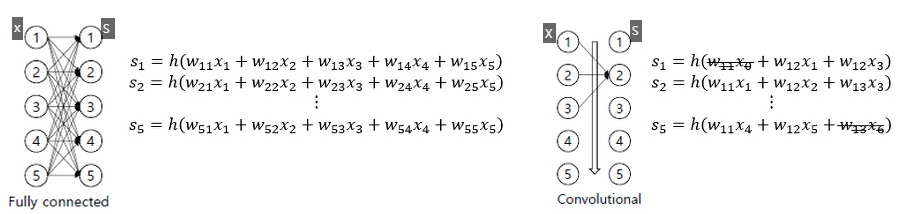
- 이미지 데이터는 픽셀 데이터간의 연관성이 중요하고 Locality, Spatiality 특성을 살려야 한다. 그렇기 때문에 일반적인 DNN과 같이 노드를 직렬화 하지 않고 아래와 같은 2D(혹은3D) 형식으로 인풋 데이터의 위치적 특성을 살려준다.
- CNN의 기본 아키텍쳐는 아래와 같이 1.Conv→2.ReLU→3.Maxpooling(1~3 여러번반복)→4.FC Layer 로 구성된다.
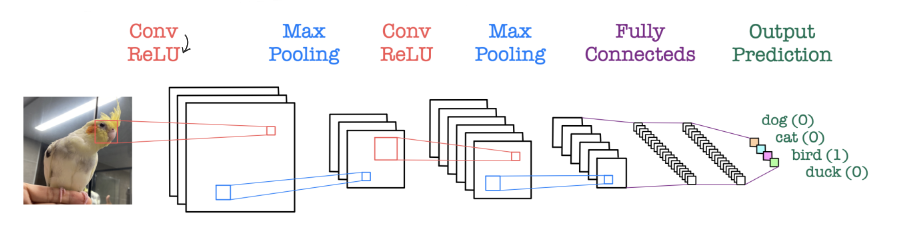
그럼 아래에서는 각 단계 Convolution , Maxpooling, FC layer의 역할에 대해 자세히 알아보자.
Convolution
- Convolution layer는 kernel(filter)를 사용하여 spatial relationship을 보존하면서 feature extraction 하는 과정이다. filter는 곧 sharing weight와 같은 의미이다.
- 아래 그림과 같이 Input data를 filter를 통해 elementwise multiply 한뒤 sum 하여 featuremap(output)을 만든다.
- CNN에서는 input의 크기가 얼만큼 크던 filter size만큼의 parameter(=filter안에 원소들)만 학습하면 된다.
- filter와 kernel은 비슷한 개념인데, 하나의 filter안에 input의 채널개수 만큼의 kernel이 있다고 보면된다. 예를들어 RGB 3개짜리 input image로 부터 10개 feature map을 생성하려면 filter는10개, kernel은 30개 필요하다
- stride는 filter를 몇칸 씩 움직일지를 나타낸다. 아래와 같이 5×6 을 stride=1로 conv하면 3×4 사이즈로 반환된다. 이 경우 size가 작아지는 이유가 가장자리 원소들이 한번씩만 계산되기 때문인데, 가장자리 정보가 중요한 경우에는 가장자리 둘레를 0으로 한층 더 만들어주는 zero-pedding 방법을 이용한다.
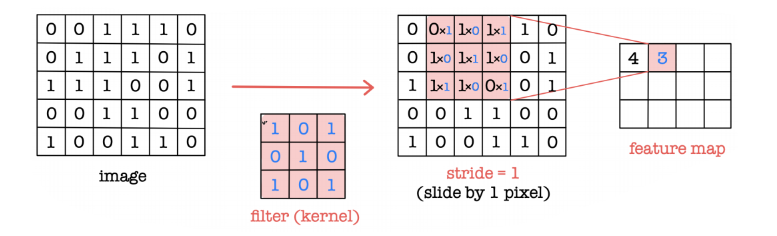
아래 그림을 하나씩 들여다 보면서 전반적인 Convolution 과정을 이해해보자.
- Input image 는 32×32 크기의 이미지가 3개 채널로 구성되어있다.
- 첫번째 conv layer에서는 3×3 size의 kernel 3개로 이루어진 filter를 6개사용했기에 30×30 짜리 featuremap이 6장 나온다. 크기다 map size가 32→30 으로 줄어든 이유는 stride=1에 zero-pedding을 하지 않았기 때문이다.
- 첫번째 layer 에서 parameter 개수는 몇개일까? (3×3×3+1)×6개 이다. 3×3은 kernel size, 3은 kernel개수, 1은 bias, 6은 filter개수이기 때문이다.
- 따라서 Convolution 의 4가지 주요 hyper parameter는 kernel 사이즈, filter의 개수, stride, padding 이 된다.
- 직후에 Max pooling 을 거치게 되면 feature map의 개수는 변하지 않고 map size만 줄어든다.

큰 size의 filter를 한번 쓰는 것 vs 작은 filter를 여러번 쓰는 것
- 아래 그림과 같이 Receptive field(원천이 되는 영역)이 7×7 size로 동일하다고 가정했을 때, ① 7×7 kernel을 1번 conv하는것 ② 3×3 kernel을 3번 conv 하는것을 비교해보면, 두 가지 방법 모두 1개 point로 모인다.
- 하지만 ②방식이 학습할 parameter의 개수와, computation 횟수가 현저히 적으면서, ReLU를 2번 더 많이 사용함으로서 nonlinearity가 많기 때문에 더 좋은 feature를 생성한다

Max pooling
- Max pooling은 일종의 down sampling 과정으로 목적은 2가지 이다. ① Dimension reduction (마지막 FC layer를 위해 차원을 점차 줄여나간다) ② Translation Invariance (filter size보다 작은 크기의 shift에 invariance 하다)
- Max pooling은 단순히 filter size내에 있는 가장 큰 값을 취하는 것이고, 때문에 학습해야할 파라미터가 없다.
- input과 output의 feature map 개수가 변하지 않는다.
- 최대값 대신 평균값을 가져오면 Average pooling이다.

Fully Connected (FC) layer
- Convolution과 Maxpooling을 반복적으로 거친 뒤 최종 extraction된 feature들은 직렬화(flatten)되어 FC layer의 input으로 사용된다. 따라서 최종 feature map의 size와 개수가 너무 크지 않아야 한다.
- 이후에는 기존의 MLP 방식으로 주로 classifiaction 문제를 풀게된다. (은닉층은 여러개일 수 있음)

반응형
'Study > DL' 카테고리의 다른 글
| CNN - 3편 (Up-sampling, U-Net) (0) | 2023.06.30 |
|---|---|
| CNN - 2편 (Bottleneck, ResNet,Dropout) (0) | 2023.06.29 |
| Dropout 과 Batch Normalization (0) | 2023.06.29 |
| 활성화함수(Activation function)와 Optimizer (0) | 2023.06.29 |
| 역전파(Backpropagation)와 Vanishing gradient (0) | 2023.06.29 |




댓글