반응형
트랜스포머의 전반적인 구조와 Self-attention에 대해..
대부분의 이미지는 Jay Alammar 의 블로그에서 가져왔다.
- 트랜스포머의 전체적인 구조는 인코더와 디코더를 여러 개 (보통은 같은 개수만큼) 쌓은 구조이다. 직전 포스팅에서 설명한 S2S+attention 에서는 인코더/디코더가 1개였던 것과 대조된다.
- 또한 S2S 와는 다르게, 한번에 하나의 토큰씩 순차적으로 시퀀셜 하게 토큰을 처리하지 않는다. RNN 구조를 완전히 벗어나기 때문에 그럴 필요가 없다. 전체 문장(시계열에서는 타임스텝)을 한 번에 집어넣고 처리한다.
- Encoding vs Decoding block 차이점 : Encoder 는 한번에 모든 시퀀스를 다 사용함 (Unmasked), Decoder는 단어를 생성해야하니 순차적으로 생성함 (마스킹이 되어있음 Masked). 아래 그림으로 예를들어 4번째 단어(Order)를 생성하는 과정에서 인코더에는 4개 토큰이 한번에 다 들어가고, 디코더에서는 4번째 단어를 마스킹한뒤에 인풋으로 들어감 (그래서 Masked Self-attention). 또한 Decoder에는 Encoder-Decoder 레이어가 하나 더 있다. (Self-attention을 두 번 함)
- 디코더의 인풋 데이터는 학습과정에서는 타깃 시퀀스의 직전 스텝까지의 시퀀스가 되고, 추론과정에서는 직전 스텝까지 디코더가 생성한 시퀀스가 된다.

- 트랜스포머의 전체적인 구조를 보면 아래와 같다. (오른쪽 그림이 왼쪽그림을 좀 더 풀어서 그림)
- Self-attention 이 Mult-head라서 화살표가 여러 개 꽂혀있는 점과 인코더의 마지막 출력값이 모든 디코더 블락의 Encoder-Decoder self attention layer의 인풋으로 들어가는 점을 눈여겨봐야 한다.
- Multi-head, Positional Embedding, Residual block에 대해서는 아래에서 좀 더 자세히 정리한다.

1. Input Embedding과 Positional Encoding
- Input embedding 은 입력데이터가 텍스트일 때는 주로 워드임베딩이나 글로브(GloVe) 등을 사용한다. 논문에서는 임베딩을 통해 인풋데이터의 차원을 512로 맞춰준다.
- Input embedding 은 첫 번째 인코더 블록에만 사용되기 때문에, 각 인코더 블록의 출력은 512로 유지되야 한다.
- 입력의 크기 (size of vector)는 Input embbedding으로 정하고, 시퀀스의 길이 (size of list)는 하이퍼파라미터로 따로 지정해야 한다 (보통은 학습 데이터에서 가장 긴 문장의 길이로 정한다)
- 트랜스포머는 한 번에 전체 시퀀스를 통으로 집어넣기 때문에 어떤 단어가 몇 번째에 위치하는지에 대한 정보가 손실된다. 이 정보를 보존하고자 하는 방법이 Positional Encoding이다.
- 좋은 Positional Encoding의 조건 :
- 모든 단어(토큰)들이 같은 크기로 변환되야한다
- 인풋 시퀀스에서 두 토큰의 거리가 멀어지면 Positional Encoding을 거치게 된 후에도 멀어야한다.
- 실제로 Positional Encoding 을 하는 과정에 대한 자세한 설명은 생략 (삼각함수를 이용함). 다만 왼쪽 그림과 같이 Positional Encoding 한 결과와 Input embedding 한 결과를 더한다 (concat이 아님에 주의)

- 이렇게 최종 임베딩이 되고 나면 Encoder의 Self-Attention layer와 FFN에 들어가게 된다.
- Self-Attention layer에서는 서로 간에가 있다 : z1 은 x1, x2 모두와 연관이 있고, z2 도 x1,x2 모두와 연관이 있다. 서로서로 연관이 있다
- Feed forward layer에서는에서는 서로간에 dependency 가 없다 : r1,r2 는 각각 z1,z2 랑만 연관이 있다. r1 은 z2과 연관이 없다. FFN 은 토큰 단위로 따로따로 적용되기 때문이다 (네트워크 자체는 구조와 파라미터가 완전히 동일한 하나의 네트워크다). r1, r2는는 두번째 인코더의 인풋으로 사용된다.
- Self attention을 자연어처리 예시로 생각해 보면... The animal did not cross the street because it was too tired라는 문장이 있었을 때 it it이라는 단어가 결국 animal animal이라는 것을 인공지능 모델이 이해할 수 있게 도와주는 과정이다. (오른쪽 그림) it에 대한 임베딩 결과를 보면 The The와 animal animal에 집중하고 있음을 알 수 있다

2. Self-Attention
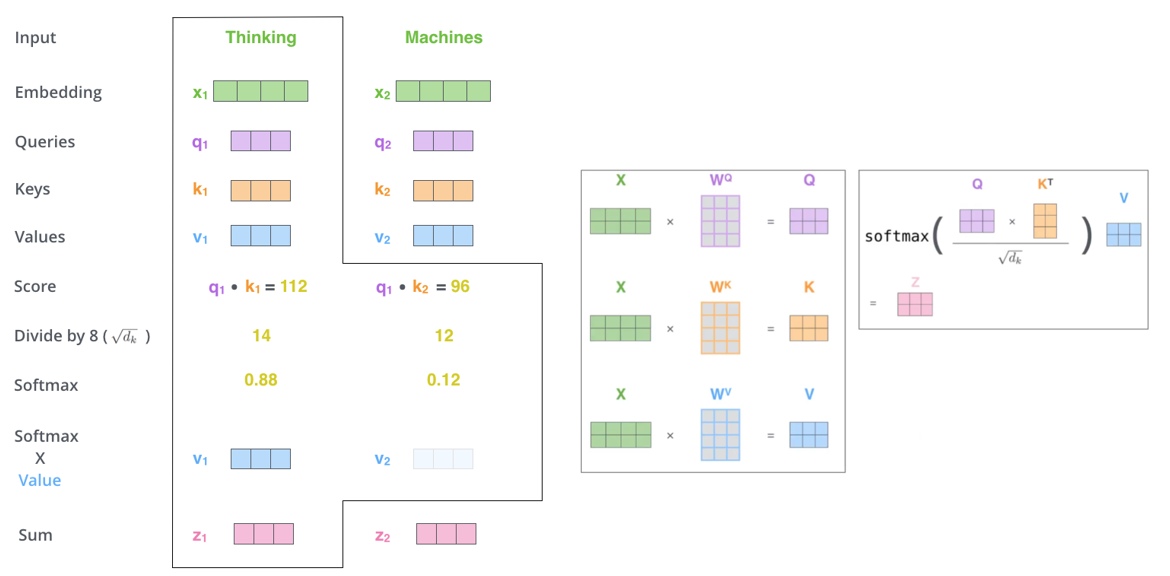
Step1 : 인코더의 인풋 벡터로부터 Query (Q), Key (K), Vector (V) 3가지의 벡터를 만든다.
- Query : 쿼리는 물어보는 주체다. 현재 보고 있는 단어(토큰)의 representation이고, 다른 단어들의 score를 매기기 위해 기준이 되는 값이다. 따라서 쿼리는 현재 작업하고 있는 단어에 대해서만 신경 쓰게 된다.
- Key : 키는 물어보는 대상이다. 우리가 가지고 있는 단어들의 라벨과 같은 역할을 한다. 쿼리가 주어졌을 때 그 쿼리에 해당하는 relevant 한 단어들을 찾을 때 말 그대로 key (identity) 역할을 한다고 보면 된다.
- Value : 실제 각 단어들의 attention score 계산을 위한 값이라고 보면 된다.

- Q, K, V 를 만드는 방법은 : 인풋 벡터에 Q,K,V 각각에 해당하는 matrix를 곱한다. attention layer의 학습과정에서 이 3개의 matrix의 각 원소들이 학습된다. 예를 들어 그림에서 X_1 × W_Q = q_1 이 된다.
- 일반적으로 Q,K,V 는 인풋벡터보다 작은 사이즈로 임베딩 한다. Multi-head attention 이기 때문에 마지막에 벡터들을 concat 한 뒤에 인풋벡터와 같은 사이즈가 나와야 하기 때문이다.
- 예를 들어, 8개로 구성된 Multi-head attention의 경우 512 → 64차원으로 임베딩하게 된다. (64 ×8 = 512)

Step2 : 인풋벡터에 대해 다른 토큰들과의 score값을 계산한다.
- 먼저 query query와 key 를 곱한 뒤, key vector의의 차원수의 제곱근으로 나눠준 뒤 softmax취함.
- 이때 softmax score의 의미는 내가 보고있는 단어(토큰)에 얼마나 중요한 역할을 하는가를 의미함
- 각 토큰에 해당하는 value vector에에 softmax값을 곱해준다.
- 마지막으로 output(z)은 모든 토큰에 대한 value vector를 더해서 만든다.
- 이 과정을 모든 입력 토큰에 대해서 실행한다.
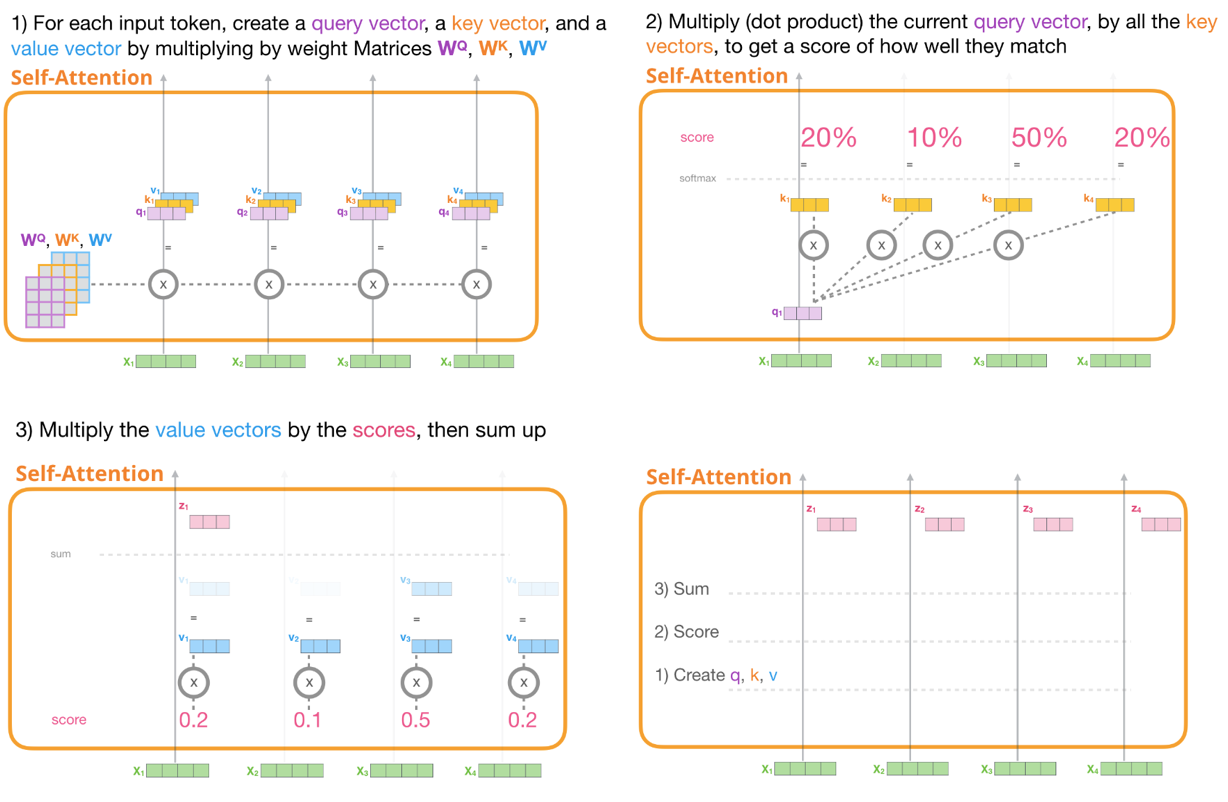
- 아래 그림을 순서대로 따라가 보면 Self attention 과정에 대해 조금 더 쉽게 이해할 수 있다.
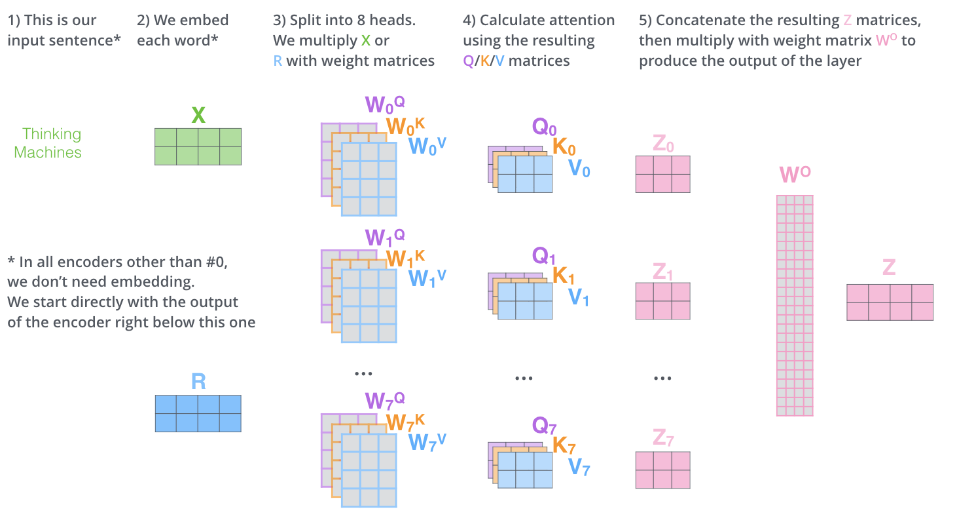
Multi-head attention
- 트랜스포머에서는 모델이 입력 시퀀스의 다양한 부분에 동시에 집중하여 더 풍부한 정보를 학습할 수 있게 하기 위해 Multi-head attention을 사용한다. 앞서 설명한 self attention 을 여러 번 해서 concat 한 뒤 최종 출력을 만든다.
- 아래 예시의 경우 8 개 헤드의 각 출력 Z_0 ~ Z_7을 concat 하면 (2,24) 사이즈로 입력 벡터의 크기 (2,4)와 맞지 않아 output weight matrix (W_o)를 (24,4) 사이즈로 만들어서 X의 차원크기를 유지해 준다.
- 보통은 각 attention layer의 출력(z)을 인풋(x)의 차원크기 ÷ 헤드개수로 한다. (W_o 가 정사각 행렬이 되도록)
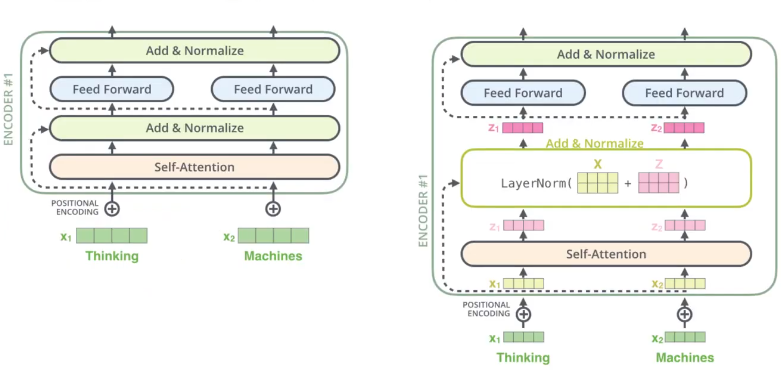
3. Residual과 Position-wise Feed Forward Networks
Residual (Add & Normalize)
- ResNet에서의 residual block과 동일하다. Self attention의 입력값과 결괏값을 더 해준 뒤에 normalize 하는 과정
- Residual 은 모든 인코더와 디코더 블록의 모든 attention 및 feed forward layer 뒤에 붙는다.
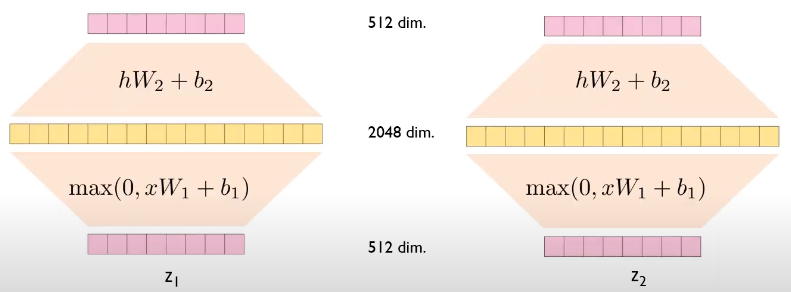
Point-wise Feed forward Network
- FFN 은 인풋의 모든 포지션에 대해 동일하게 적용된다 : Apply to each position seperately and identically
- FFN(x) = max(0, x*W1+b1)*W2+b2 : max 값을 취한다는 것은 ReLU를 적용한다는 것
- Encoder 안의 각 FFN 은 동일하기 때문에 (W,b 를 공유하기 때문에) size가 1인 커널을 여러 번 적용하는 컨볼루션 레이어라고 생각하면 쉽다. 정확히 말하면 2개의 컨볼루션 레이어가 있고, 첫번째 레이어에서는 커널을 2028번, 두번째 레이어에서는 512번 사용한것
여기까지가 트랜스포머의 Encoder 파트... 아래서부터는 Decoder 파트에 대한 설명이다.
Decoder의 첫 번째 레이어 : Masked Multi-head Attention
- 디코더에서의 첫번째 attention layer의 가장 큰 특징은, 인코더와 다르게 마스킹되어있다는 점
- Only allowed to attend to early positions : 당연하게도 자신보다 앞쪽 포지션만 참고할 수 있다.
- Self attention에서 마스킹을 하는 방법은 attention score 값에 - inf (∞) 값을 부여하는 것 → Softmax 값이 0 이 되도록
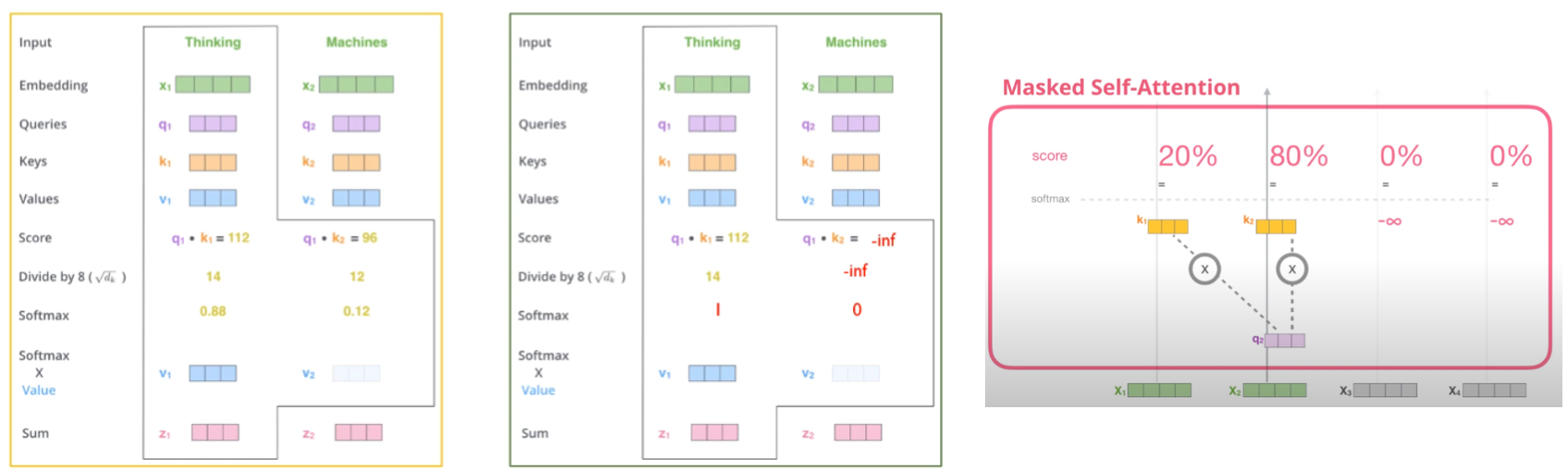
- 전체적인 과정은 아래와 같다

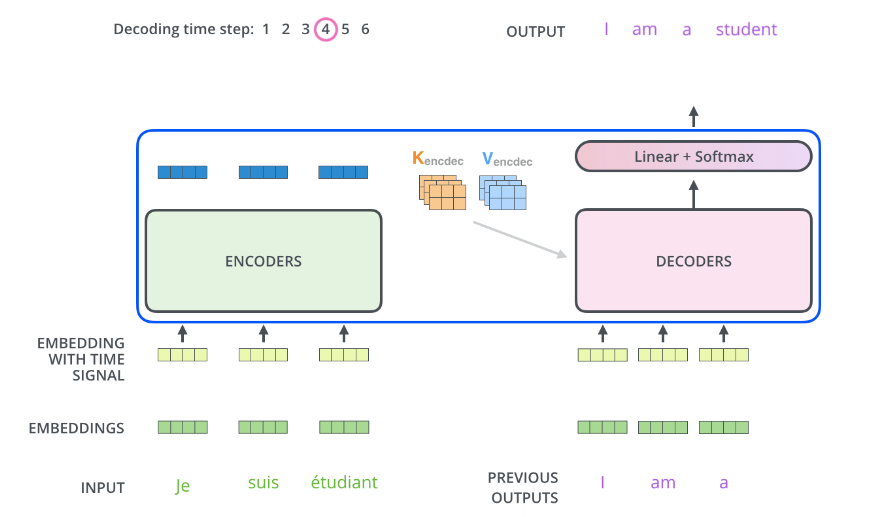
Decoder의 두 번째 레이어 : Encoder-Decoder layer
- 첫 번째입력으로는 Output 의 임베딩값이 들어갔다면, 두번째 attention layer의의 입력으로는 ① 마지막 인코더의 아웃풋이 Key와 Value로 들어가고 ② 디코더의 첫번째 어텐션 레이어의 아웃풋이 Query로 들어가게 되고, 이 둘 사이의 어텐션을 계산하게된다.
- 포스트 처음 부분에 설명한 것처럼 Decoder 에 들어가는 output은 shifted right 되며 시퀀셜하게 들어간다.
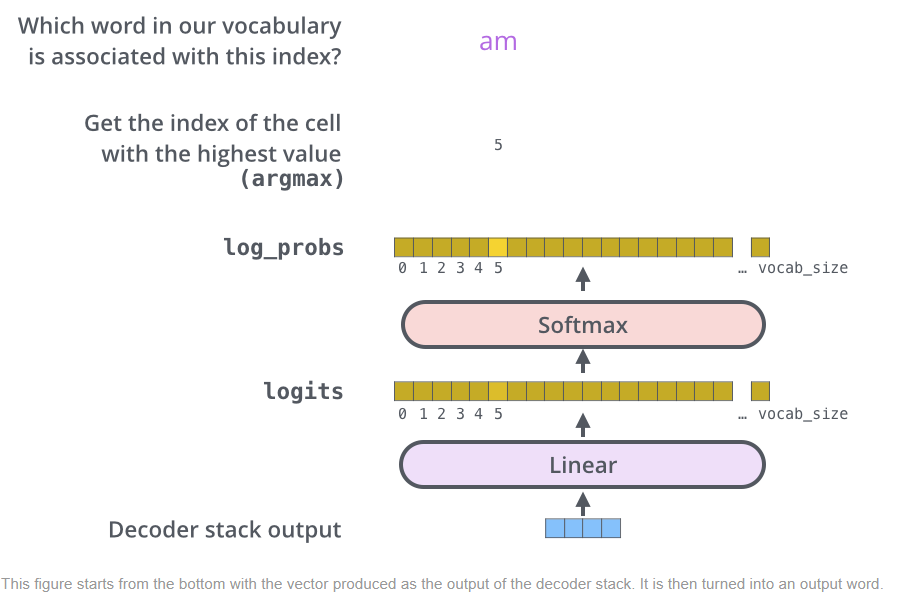
The final linear and softmax layer
- Linear layer는 간단한 fully connected neural network이고 softmax layer는 이를 확률값으로 바꿔주고, 마지막으로 argmax 인 인덱스에 해당하는 단어를 반환하게 된다.
반응형
'Study > 시계열' 카테고리의 다른 글
| 7. (Transformer-1편) RNN 과 Attention (1) | 2024.07.24 |
|---|---|
| 6. 시계열 데이터 클러스터링 (DTW, TimeSeriesKMeans) (0) | 2024.07.09 |
| 5. Seq2Seq 모델을 이용한 다변량 다중시점 시계열 예측 (1) | 2024.07.08 |
| 4. Prophet 패키지를 이용한 간단 시계열 예측 (0) | 2024.07.08 |
| 3. 딥러닝을 이용한 시계열 예측 (TensorFlow, LSTM) (1) | 2024.07.08 |




댓글